Вы просматриваете документацию для Kubernetes версии: v1.28
Kubernetes v1.28 документация больше не поддерживается. Версия, которую вы сейчас просматриваете, является статической. Для актуальной документации см. последнюю версию.
Архитектура для сбора логов
Логи помогают понять, что происходит внутри приложения. Они особенно полезны для отладки проблем и мониторинга деятельности кластера. У большинства современных приложений имеется тот или иной механизм сбора логов. Контейнерные движки в этом смысле не исключение. Самый простой и наиболее распространенный метод сбора логов для контейнерных приложений задействует потоки stdout и stderr.
Однако встроенной функциональности контейнерного движка или среды исполнения обычно недостаточно для организации полноценного решения по сбору логов.
Например, может возникнуть необходимость просмотреть логи приложения при аварийном завершении работы Pod'а, его вытеснении (eviction) или "падении" узла.
В кластере у логов должно быть отдельное хранилище и жизненный цикл, не зависящий от узлов, Pod'ов или контейнеров. Эта концепция называется сбор логов на уровне кластера.
Архитектуры для сбора логов на уровне кластера требуют отдельного бэкенда для их хранения, анализа и выполнения запросов. Kubernetes не имеет собственного решения для хранения такого типа данных. Вместо этого существует множество продуктов для сбора логов, которые прекрасно с ним интегрируются. В последующих разделах описано, как обрабатывать логи и хранить их на узлах.
Основы сбора логов в Kubernetes
В примере ниже используется спецификация Pod с контейнером для отправки текста в стандартный поток вывода раз в секунду.

apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Запустить его можно с помощью следующей команды:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Результат будет таким:
pod/counter created
Получить логи можно с помощью команды kubectl logs, как показано ниже:
kubectl logs counter
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Команда kubectl logs --previous позволяет извлечь логи из предыдущего воплощения контейнера. Если в Pod'е несколько контейнеров, выбрать нужный для извлечения логов можно с помощью флага -c:
kubectl logs counter -c count
Для получения дополнительной информации см. документацию по kubectl logs.
Сбор логов на уровне узла
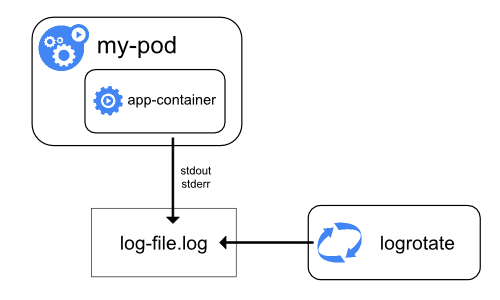
Среда исполнения для контейнера обрабатывает и перенаправляет любой вывод в потоки stdout и stderr приложения. Docker Engine, например, перенаправляет эти потоки драйверу журналирования, который в Kubernetes настроен на запись в файл в формате JSON.
По умолчанию, если контейнер перезапускается, kubelet сохраняет один завершенный контейнер с его логами. Если Pod вытесняется с узла, все соответствующие контейнеры также вытесняются вместе с их логами.
Важным моментом при сборе логов на уровне узла является их ротация, чтобы логи не занимали все доступное место на узле. Kubernetes не отвечает за ротацию логов, но способен развернуть инструмент для решения этой проблемы. Например, в кластерах Kubernetes, развертываемых с помощью скрипта kube-up.sh, имеется инструмент logrotate, настроенный на ежечасный запуск. Также можно настроить среду исполнения контейнера на автоматическую ротацию логов приложения.
Подробную информацию о том, как kube-up.sh настраивает логирование для образа COS на GCP, можно найти в соответствующем скрипте configure-helper.
При использовании среды исполнения контейнера CRI kubelet отвечает за ротацию логов и управление структурой их директории. kubelet передает данные среде исполнения контейнера CRI, а та сохраняет логи контейнера в указанное место. С помощью параметров containerLogMaxSize и containerLogMaxFiles в конфигурационном файле kubelet'а можно настроить максимальный размер каждого лог-файла и максимальное число таких файлов для каждого контейнера соответственно.
При выполнении команды kubectl logs (как в примере из раздела про основы сбора логов) kubelet на узле обрабатывает запрос и считывает данные непосредственно из файла журнала. Затем он возвращает его содержимое.
kubectl logs будет доступно содержимое только последнего лог-файла. Например, имеется файл размером 10 МБ, logrotate выполняет ротацию, и получается два файла: первый размером 10 МБ, второй - пустой. В этом случае kubectl logs вернет второй лог-файл (пустой).Логи системных компонентов
Существует два типа системных компонентов: те, которые работают в контейнере, и те, которые работают за пределами контейнера. Например:
- планировщик Kubernetes и kube-proxy выполняются в контейнере;
- kubelet и среда исполнения контейнера работают за пределами контейнера.
На машинах с systemd среда исполнения и kubelet пишут в journald. Если systemd отсутствует, среда исполнения и kubelet пишут в файлы .log в директории /var/log. Системные компоненты внутри контейнеров всегда пишут в директорию /var/log, обходя механизм ведения логов по умолчанию. Они используют библиотеку для сбора логов klog. Правила сбора логов и рекомендации можно найти в соответствующей документации.
Как и логи контейнеров, логи системных компонентов в директории /var/log необходимо ротировать. В кластерах Kubernetes, созданных с помощью скрипта kube-up.sh, эти файлы настроены на ежедневную ротацию с помощью инструмента logrotate или при достижении 100 МБ.
Архитектуры для сбора логов на уровне кластера
Kubernetes не имеет собственного решения для сбора логов на уровне кластера, но есть общие подходы, которые можно рассмотреть. Вот некоторые из них:
- использовать агент на уровне узлов (запускается на каждом узле);
- внедрить в Pod с приложением специальный sidecar-контейнер для сбора логов;
- отправлять логи из приложения непосредственно в бэкенд.
Использование агента на уровне узлов
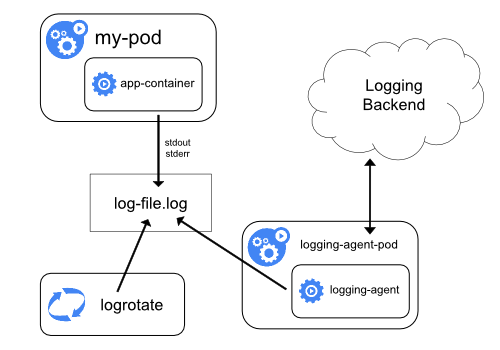
Сбор логов на уровне кластера можно реализовать, запустив node-level-агент на каждом узле. Лог-агент — это специальный инструмент, который предоставляет доступ к логам или передает их бэкенду. Как правило, лог-агент представляет собой контейнер с доступом к директории с файлами логов всех контейнеров приложений на этом узле.
Поскольку лог-агент должен работать на каждом узле, рекомендуется запускать его как DaemonSet.
Сбор логов на уровне узла предусматривает запуск одного агента на узел и не требует изменений в приложениях, работающих на узле.
Контейнеры пишут в stdout и stderr, но без согласованного формата. Агент на уровне узла собирает эти логи и направляет их на агрегацию.
Сбор логов с помощью sidecar-контейнера с лог-агентом
Sidecar-контейнер можно использовать одним из следующих способов:
- sidecar-контейнер транслирует логи приложений на свой собственный
stdout; - в sidecar-контейнере работает агент, настроенный на сбор логов из контейнера приложения.
Транслирующий sidecar-контейнер
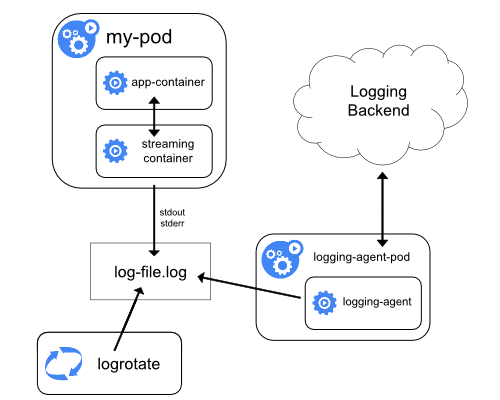
Настроив sidecar-контейнеры на вывод в их собственные потоки stdout и stderr, можно воспользоваться преимуществами kubelet и лог-агента, которые уже работают на каждом узле. Sidecar-контейнеры считывают логи из файла, сокета или journald. Затем каждый из них пишет логи в собственный поток stdout или stderr.
Такой подход позволяет разграничить потоки логов от разных частей приложения, некоторые из которых могут не поддерживать запись в stdout или stderr. Логика, управляющая перенаправлением логов, проста и не требует значительных ресурсов. Кроме того, поскольку stdout и stderr обрабатываются kubelet'ом, можно использовать встроенные инструменты вроде kubectl logs.
Предположим, к примеру, что в Pod'е работает один контейнер, который пишет логи в два разных файла в двух разных форматах. Вот пример конфигурации такого Pod'а:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Не рекомендуется писать логи разных форматов в один и тот же поток, даже если удалось перенаправить оба компонента в stdout контейнера. Вместо этого можно создать два sidecar-контейнера. Каждый из них будет забирать определенный лог-файл с общего тома и перенаправлять логи в свой stdout.
Вот пример конфигурации Pod'а с двумя sidecar-контейнерами:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Доступ к каждому потоку логов такого Pod'а можно получить отдельно, выполнив следующие команды:
kubectl logs counter count-log-1
Результат будет таким:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Результат будет таким:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
Агент на уровне узла, установленный в кластере, подхватывает эти потоки логов автоматически без дополнительной настройки. При желании можно настроить агент на парсинг логов в зависимости от контейнера-источника.
Обратите внимание: несмотря на низкое использование процессора и памяти (порядка нескольких milliCPU для процессора и пары мегабайт памяти), запись логов в файл и их последующая потоковая передача в stdout может вдвое увеличить нагрузку на диск. Если приложение пишет в один файл, рекомендуется установить /dev/stdout в качестве адресата, нежели использовать подход с транслирующим контейнером.
Sidecar-контейнеры также можно использовать для ротации файлов логов, которые не могут быть ротированы самим приложением. В качестве примера можно привести небольшой контейнер, периодически запускающий logrotate. Однако рекомендуется использовать stdout и stderr напрямую, а управление политиками ротации и хранения оставить kubelet'у.
Sidecar-контейнер с лог-агентом
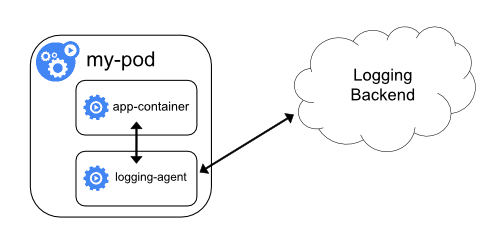
Если лог-агент на уровне узла недостаточно гибок для ваших потребностей, можно создать sidecar-контейнер с отдельным лог-агентом, специально настроенным на работу с приложением.
kubectl logs будет невозможен, поскольку они не контролируются kubelet'ом.Ниже приведены два файла конфигурации sidecar-контейнера с лог-агентом. Первый содержит ConfigMap для настройки fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Второй файл описывает Pod с sidecar-контейнером, в котором работает fluentd. Pod монтирует том с конфигурацией fluentd.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
В приведенных выше примерах fluentd можно заменить на другой лог-агент, считывающий данные из любого источника в контейнере приложения.
Прямой доступ к логам из приложения
Сбор логов приложения на уровне кластера, при котором доступ к ним осуществляется напрямую, выходит за рамки Kubernetes.